FinSightAI: Small Models. Big Financial Insight.
Fine-tuning SmolLM2 with QLoRA to redefine domain-specific reasoning in finance.
- BLEU Improvement
- +135%
- Training Time
- ~8h
- Parameters
- 1.7B
FinSightAI was engineered to bring financial literacy and analytical depth to smaller, efficient models. Through QLoRA fine-tuning, it bridges the gap between performance and practicality.
Designed for advisory systems, report summarization, and real-time financial chat agents, FinSightAI proves that you don't need massive compute to achieve massive insight.
Precision without the overhead
FinSightAI achieves enterprise-grade reasoning on consumer hardware.
Efficient Fine-tuning
Fine-tuned on RTX 3050 GPU with just 6GB VRAM, completed within 8 hours.
Parameter Efficiency
Only 280MB of additional storage through LoRA adapters.
Precision Boost
Outperforms base SmolLM2 by up to 135% on BLEU score.
Inference Speed
Retains near-identical latency to base model during inference.
Technical Snapshot
A breakdown of the QLoRA fine-tuning pipeline.
SmolLM2-1.7B-Instruct
QLoRA + PEFT + UnSloth
4-bit NF4 (NormalFloat)
NVIDIA RTX 3050 (6GB VRAM)
~16 hours
50M+ tokens from 30K+ conversations
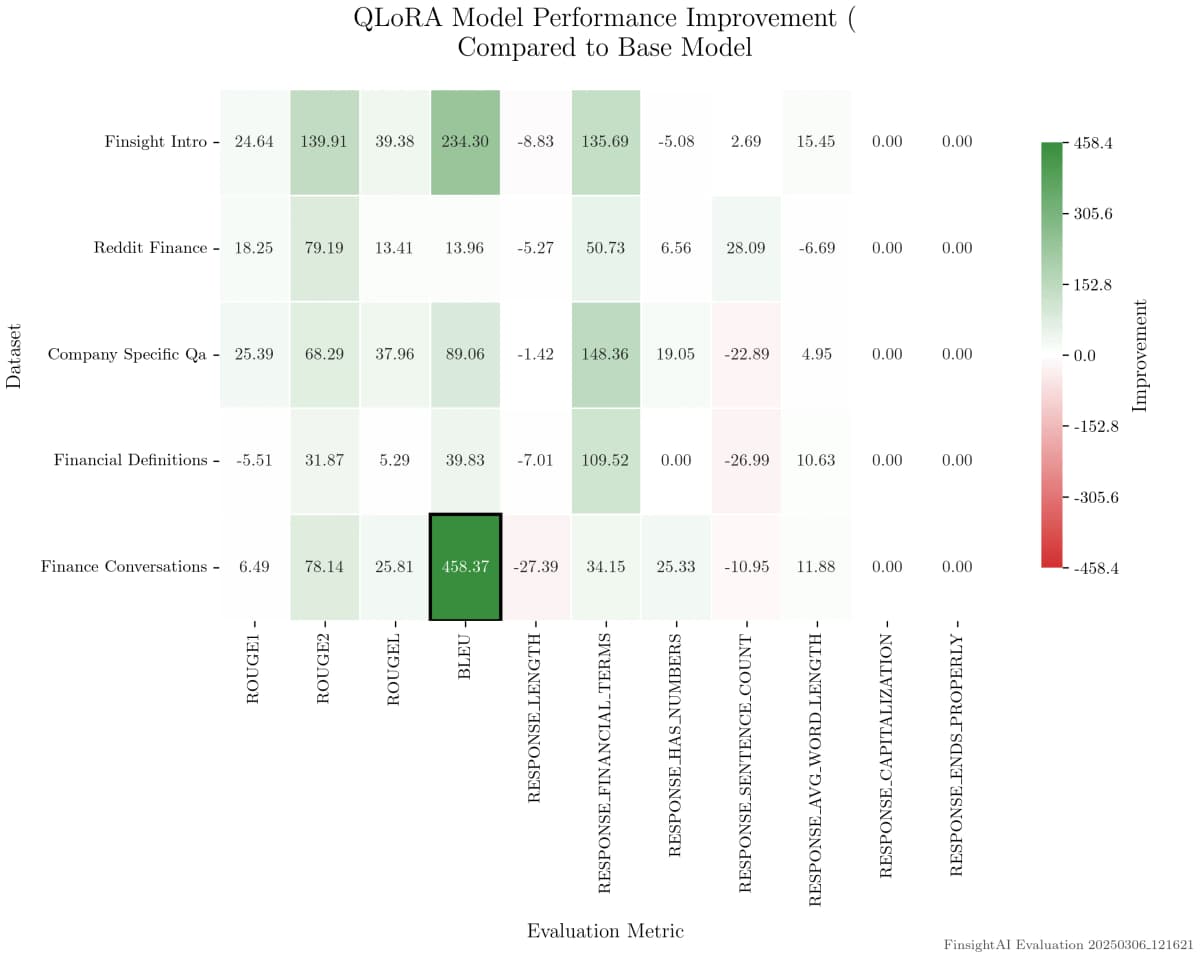
Metrics that speak for themselves
Quantitative improvements across BLEU, ROUGE, and response quality.
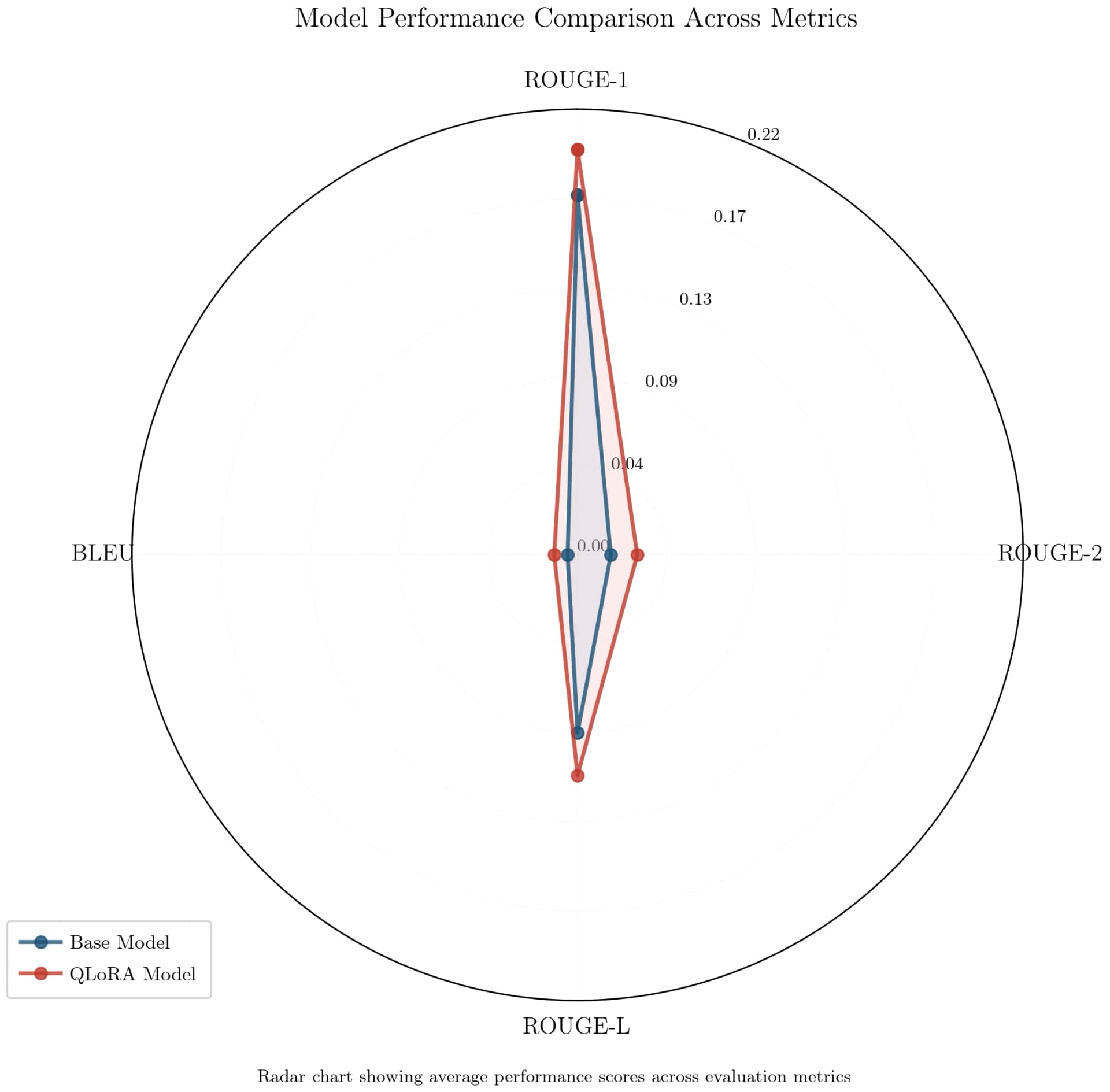
Overall Metric Distribution
Multi-dimensional radar view showing improvement across all evaluation metrics.
Base Model vs. FinSightAI
Watch the fine-tuned model reason through a real financial question.
Question
Explain the price-to-earnings (P/E) ratio and how investors use it to evaluate stocks.
Why FinSightAI matters
A statement that precision doesn't need scale.
"FinSightAI is the first compact model we trust for compliance reviews. It hits enterprise accuracy while running on a single 3050 laptop—our analysts ship insights faster without waiting for the big cluster."
Nia Mensim — Director of Quant Innovation, Helix Capital